pFind Studio: a computational solution for mass spectrometry-based proteomics
点击下载招生简章
关于我们(About us)
pFind团队计划招收硕士生2名,直博生1名,2024年秋季入学。欢迎各高校本科生报考!有意报考的学生请回答相关问题(点此超链接打开),并发送个人简历给贺思敏或迟浩老师。
常见问题
Q:请问课题组的研究方向是?
我们研究蛋白质鉴定和定量算法。先举两个例子。第一人脸识别问题:照相机拍一张人脸的图片,要求快速、准确地在一个较大人脸图片库中找到和该图片最接近的图片。再说web搜索:用户输入一个关键词,要求快速、准确地在一个较大的网页库中找到和该关键词匹配最好的网页。与以上两个问题类似,我们研究的问题是:一台专用的仪器采集一张蛋白质的图谱,要求快速、准确地在一个较大蛋白质谱图库中找到和该图谱最接近的图谱。这里面主要应用统计机器学习、模式识别和组合优化知识,核心问题是打分评价和并行加速。
对于想读硕士的同学,研究方向并不是那么重要。关键是“一进”和“一出”。“一进”就是有导师愿意招收,能进入计算所。“一出”就是在找工作的时候,多上上心,准备好笔试、面试。从技术层面讲,找工作的笔试、面试主要是考察编写带算法的程序的能力,比如二叉树。不太有公司会纠结你是哪个课题组,只看到你来自中科院计算所即可。来我们组,主要的工作就是写带算法的程序,这和在计算所其他课题组没有太大区别。当然,如果硕士的研究方向与你毕业想找的岗位有关系,自然竞争优势会大一些。这也是体现在个人实力上,与课题组关系不大。对于有志于硕博连读(直博)的同学,可以多交流,谋定而后动。
计算所有多个生物信息方向的研究团队,大家的工位都是在一起的。平时也经常在一起活动。主要看各人报考哪位老师的研究生。其实即便具体到某位老师,也是有不同的研究方向。很难界定来了一定做什么不做什么。
Q:请问课题组的具体名称是?
我们是中科院计算所生物信息实验室pFind团队,该团队由贺思敏研究员领导。pFind团队被评为2014年计算所优秀团队,每年只有一个团队能获此殊荣。我们目前隶属于计算所前瞻研究实验室。我们的办公地点在计算所8楼。
Q:保研面试或考研复试都考哪些内容?
我们的保研面试和考研复试考试形式、内容是一样的,均由笔试、机试和面试3部分组成。其中,笔试又分为数学、算法、中文和英文测试4个部分,和大学课后作业题目难度相当;机试有6道题目,需要现场编写、调试,编程时间为1小时,编程语言为C或C++,题目有难易之分,简单的题目类似于100个数的冒泡排序,难的题目需要有一定算法功底才能实现;面试需要准备一个10分钟的个人介绍PPT,要求条理清晰、详略得当,切记,千万不能有错别字,有错别字几乎必被淘汰。我们比较看重机试和面试。我们会优先考虑录取参加过ACM竞赛或数学建模比赛并获得过比较优秀的成绩的同学。这里可以透露一道必考题目:请说出主要的排序算法以及它们各自的最好、最坏以及平均复杂度。
常有非计算机专业的同学担心笔试和机试。请大家放心,我们几乎每年都会招一名非计算机专业的同学,他们本科几乎没编过程序,也没系统学习过算法。但是,这些同学总有一点或两点非常突出。面试考察的目的不是难为各位同学,而是为了大家增进了解。入组后才会面临真正的挑战。
Q:一定要参加计算所夏令营吗?
最近几年,计算所都会在7月组织夏令营活动。可以积极报名,如能来参加夏令营,可以趁此机会来组里面试。这样至少多了一次面试机会,给自己更多的选择余地。该面试内容、效力等价于上面介绍的9月的保研面试或4月的考研复试。通过组里面试的,可以为你保留一个录取名额。
如未能参加计算所夏令营,可以在9月来计算所参加组里的面试。
Q:一定要同意硕博连读吗?
我们既有直博(硕博连读)名额,也有硕士名额,你的选择不会影响面试成绩。但我们希望你的选择是严肃的、慎重的,这既是为别人负责也是为自己负责。
Q:硕士和博士的毕业要求分别是什么?一般要读几年?
我们一般要求硕士写一个软件、发一篇SCI文章。不过不会很难,因为我们几乎所有的硕士都达到了要求,而且软件和文章一般都是由高年级博士直接指导或合作完成。与计算所其他课题组一样,硕士一般3年毕业。我们对硕博连读生的培养方案是:第一年,上课,并接受组内培训;第二年,组内小轮转,向师兄师姐学习,接触我们领域内的各种问题,并确立自己的方向;第三年,开始对一个方向进行攻关,完成一篇综述,确立研究计划,接触科研项目任务;第四年,编写软件,承担项目任务,做出比较好的结果;第五年,发表1到2篇文章,完善软件,指导新生工作;第六年,撰写博士毕业论文,与低年级同学交接工作,顺利毕业。当然,如果能够大四进入课题组或自己比较努力,5年毕业也不是没有可能。
Q:需要掌握很多生物知识吗?
前面说过,我们的核心问题全是计算问题,生物知识只在提取特征时用到,不需要特别钻研。当然,如果你特别有兴趣,我们的生物合作方也会给你提供亲手做生物实验的机会。
Q:硕士和博士的毕业去向如何?好找工作吗?
我们的硕士目前的主要毕业去向是出国读博和去国内互联网公司。如果是去北美高校读博,提供offer的学校一般都是Top50以内。如果是去国内互联网公司,年薪一般在30万左右。博士主要去向是出国读博后或留所当老师。大家可以看member网页中的former member获取更多信息。这里面是pFind团队所有毕业生的目前工作情况。
贺思敏老师关于我们团队的介绍:
所谓质谱鉴定蛋白质问题,就是给定一个生物样品,我们想鉴定其中包含哪些蛋白质成分。蛋白质分离、电离之后进入生物质谱仪,碎裂之后生成一个数字化的质谱图,其横轴是蛋白质片断离子的质量电荷比即质荷比,纵轴是离子强度计数,因此一个质谱图相当于一个直方图。我们要从这个数字化质谱图反推出生成它的蛋白质是什么。下面就是一台高精度生物质谱仪生成的一个质谱图。
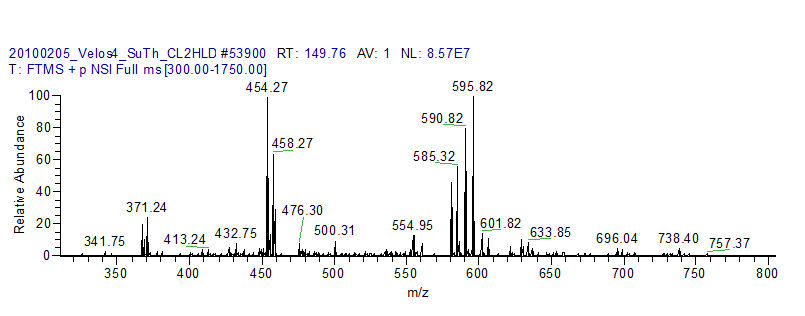
质谱仪很神奇,因为迄今为止已经有六位与质谱仪发明、发现相关的诺贝尔奖得主,而且如果各位熟悉基因组测序仪及其巨大威力的话,那么质谱仪就是蛋白质层次的测序仪。质谱仪也很平凡,因为就计算而言,它与数码相机、核磁共振仪、断层扫描仪没有本质区别,只是一种新的数字化仪器而已,而且质谱图看起来比图像还简单一些,因为图像一般是二维坐标下的强度图,而质谱图是一维坐标下的强度图。
质谱鉴定蛋白质,其实与图像处理、人脸识别没什么本质区别。不仅如此,质谱鉴定蛋白质与文本检索(比如我们常用的谷歌、百度检索)也高度相似。所有这些问题,都属于一个领域,就是信息检索。而我们团队的任务,就是研究一个特定的信息检索问题——质谱鉴定蛋白质,开发一个特定的搜索引擎——pFind。
pFind的命名中,p代表蛋白质(protein)或者蛋白质片段(peptide, 也称肽段),Find就是搜索、鉴定之意。pFind既是我们的搜索引擎名称,也是我们团队的名称,团队每个成员都是pFinder。pFind的Founder是高文教授,2002年他凭借人脸识别、手语识别等领域的工作基础成功申请到国家973项目“生命科学若干前沿与交叉问题研究”第7课题“基于信息技术的蛋白质组研究”,我负责实施并逐渐接手。这样算起来,pFind已经有接近10年的发展历史了。
那么,经过近10年的努力,pFind达到什么水平了?首先,自然是一系列文章的突破,大家可以看pFind网站Publications栏目所列,蛋白质组学三大国际期刊MCP、JPR、Proteomics,生物信息学国际期刊Bioinformatics,生物信息学国际会议ISMB,计算蛋白质组学国际会议RECOMB-CP,美国国家科学院院刊PNAS,本领域最好期刊之一Nature Methods我们都已经突破,正在向更高层次迈进。其次,是pFind系列软件的突破,大家可以看pFind网站首页所列 Software,从核心引擎到预处理与后处理、从数据库搜索到从头测序、从单肽段鉴定到交联肽段鉴定、从定性鉴定到定量分析,丰富的软件工具形成一个平台,可以支持一个质谱/蛋白质组学实验室日常科研和服务工作。特别地,pFind软件成功鉴定核心岩藻糖化修饰蛋白质的工作发表在MCP, pNovo软件成功鉴定线虫纲精子活化标记蛋白质的工作发表在PNAS。第三,是国内外影响的扩大,大家可以看pFind网站Benchmark栏目,其中有我们几年来参加国际评测活动的信息; Friends栏目,其中有我们的国内外朋友和合作者的信息;CNCP栏目,其中有我们主办的第一届和第二届中国计算蛋白质组学研讨会的信息;Download栏目,自2010年5月开放至2012年底,国内外注册下载pFind软件数目已经达到745套,其中国内507套,国外238套。
pFind当前的发展优势有多个方面。首先,时势造英雄,作为生物信息学比较年轻的一个新分支,以基于质谱技术的规模化蛋白质鉴定为核心内容的计算蛋白质组学及其应用正在国内外蓬勃发展;基因组测序的今天就是蛋白质鉴定的明天,断层扫描仪、核磁共振仪的今天就是生物质谱仪的明天。年轻时不犹豫,年老时才能不后悔。其次,经过十年多的持续努力,我们已经掌握了蛋白质鉴定搜索引擎设计与实现的完整技术,因此也就比较容易地实现了从常规单肽段鉴定到非常规的肽段交联鉴定的发展,再进一步的跨越相信也万变不离其宗。第三,我们与高水平的质谱/蛋白质组学团队有非常密切的合作,我们的工作态度和工作能力赢得了同行的信任,所以我们不断接触重要的问题、高质量的数据,合作产出高质量的文章,利用软件优势进一步服务国内外同行,推动本领域的良性发展。第四,我们背靠计算所,曙光、龙芯团队可以为我们提供集群、多核、众核等超级计算硬件支持,文本、多媒体、跨媒体信息检索团队可以为我们提供搜索引擎设计等核心软件技术支持,在这个技术平台支持下的pFind具有独特的竞争优势。第五,也是最重要的,我们的团队,特别是新一代pFinder快速成长,他们对本领域的前景充满信心,对于自己的作品充满自豪,这是pFind的希望所在;无论将来他们走到哪里,都将对中国计算蛋白质组学做出独特的贡献。
未来的十年,pFind团队将秉承“伤其十指,不如断其一指”的原则,继续做好pFind的算法、软件、推广。一个人,一个团队,一辈子能把一件事情做好、做透,已经很不容易了。希望不远的将来,中国的生物/质谱/蛋白质组学工作者可以放心地使用中国人自己的软件,使用自己的仪器,研究自己的问题,造福自己的同类。每一个领域,每一个职业,都有自己的责任,都有自己的尊严。我们欢迎有志气的青年学生加入pFind团队,开创属于自己的未来!
领域内小同行,美国纽约大学Svetlov Vladimir博士对pLink相关工作的评价:
One got to wonder why there are more reviews about the supposed power of CXMS/XLMS than there are exploratory papers employing this method. Well, don't wonder anymore. The reason for this the main one is that XLMS critically depends on the software for X-link discovery. And most of the ones I tried and I tried really hard and for a really long time - they suck. Not just from coding point of view, clunky, flaky, and buggy, but the search algorithms suck too. Actually, just before I started using pLink I felt that the whole field is some sort of a pyramid scheme and the method is really not a workable one, at least not outside the labs who "pioneered" it. pLink in my experience is the only software that performs well for automated X-link discovery (as in not requiring an expert mass spectrometrist to validate every bloody spectrum). I have done extensive structural and biochemical validation of this technique - took a while actually to get me believing in XLMS again - and I can state it with an authority. And a gratitude. pLink can be improved but it works, out of the box. That's more than I can say about anything else I tried out there. (pLink Forum, 8/21/13)
翻译:有件事儿让人不得不纳闷儿,为什么在交联质谱(CXMS/XLMS)领域,综述文章比研究文章还多。得了,别再猜了。这个现象的原因——主要原因——是交联质谱技术极度依赖软件。而我试过的大多数软件——我真的很认真,而且真的试了很长时间——它们都很烂。不仅仅是编码烂:笨重、古怪、错误百出,鉴定算法也很烂。实际上,在我开始使用pLink之前,我感觉整个交联质谱领域像是某种非法传销,方法根本玩不转,起码在那些所谓“先驱”的顶级传销者实验室之外是如此。pLink,在我的经历中,是唯一一个可以做到自动鉴定交联谱图的软件(即不需要质谱专家去确认每一张该死的质谱图)。我对此做了广泛的结构和生物化学验证——很花了一段时间才重新唤起我对交联质谱技术的信心——因此我可以很有权威性地这样讲。并且带着感激之情。pLink还可以改进,但是它现在就能用,开箱即用。这比我试过的其他软件好多了。(转自pLink论坛,2013年8月21日)
后记:Vladimir博士畅快淋漓吐槽了其它CXMS软件。不到半年,他在《Nature》杂志上发表了文章,文中使用了我们组开发的pLink和pLabel软件。Vladimir博士表示“Many Thanks for pLink”。(pLink Forum, 11/23/13)。
王乐珩关于我们团队的介绍:
我进入现在在做的ODPS组的方法是,在他们都在客户现场加班的时候,参加进去每天一起加班到半夜。要来上百页的用户手册,把里面几百条指令一条一条动手试用了一遍。然后花两天时间写了一个教新用户上手的《入门手册》,并且提交了若干个测试中发现的bug。再早,还在pFind蛋白搜索引擎的时候,去生物学家的实验室收集软件需求。就陪着他们杀老鼠,熬夜做实验,每2小时闹钟叫醒添加试剂并记录数据,在高辐射或剧毒环境下处理试验样品。最重要的,和他们一起体会,因为生物信息数据软件设计考虑不周导致前面的一切都必须再做一遍时,那种巨大的愤怒和无奈。
刘超的说明:王乐珩在pFind团队时负责指导大家编写pFind系列软件。学生中,老一代pFinder称乐珩师兄,新一代pFinder称王老师。乐珩师兄曾经在阿里巴巴任ODPS项目经理。阿里的一系列关于云与大数据的项目、比赛、培训都是其负责或参与组织的。想毕业后以产品经理为职业的同学,可以看看乐珩师兄的博客。现在,乐珩师兄和朋友一起开创了自己的生物信息公司。
迟浩关于我们团队的介绍:
不知不觉,我在pFind团队已经度过了七年时光。pFind团队是个充满朝气的团队,无论是成熟稳重的老师还是风华正茂的新同学,这里的人们从来就没有停息过一颗进取的心,年轻不只是年龄,更是一种态度;pFind团队是个勤奋好学的团队,无论博士生还是硕士生,加入便意味着拼搏,意味着你要承担起pFind团队的希望,当然,走出这扇门后你会发现自己无意间已经硕果累累;pFind团队还是个友好和睦的团队,是一个家,这里的人们有个共同的名字:pFinder。从学生到员工,不变的是pFinder的真诚和执着。欢迎对机器学习、组合优化、信息检索与生物信息等方向有兴趣的同学加入我们。人生道路上,相信你会不虚此行。让我们共同成功,共同成长!
刘超关于我们团队的介绍:
pFind团队是一个有理想、有追求的大家庭。来这个团队的每一个人都不会过得轻松,但是不轻松意味着对自己的磨练,意味着未来的成功。我们团队各位同学的性格都偏低调,追求踏实做事、真诚待人的风格。对喜欢安心科研、反感浮躁环境的同学来说,这里大概是最适合你的一片净土之一。欢迎有志于从事应用算法、信息检索、生物信息等研究方向的同学报考!
张昆关于我们团队的介绍:
pFind是一个充满朝气,欣欣向荣的大家庭,也是一个可以尽情施展自己能力和才华的地方。在这里,你可以发现许多有趣的研究问题,接触到各种新奇的、前沿的计算方法。pFinder正在不断地向着更高水平的杂志冲刺,欢迎各位有志之士加入我们pFind,同我们一起奋斗!
樊盛博关于我们团队的介绍:
用计算机研究生物——pFind组喜欢结合两个领域两种技术。喜欢尝试新鲜事物?喜欢探索全新的未知领域?喜欢做不一样的自己?欢迎尝试——pFind。
融洽,进取,新奇。你值得拥有。
曾文锋关于我们团队的介绍:
不要认为不懂生物,就对生物信息学望而却步,我的生物知识绝对不会超过你;不要认为有生物二字,就较计算差之甚远,其实生物才是最需要计算的领域之一。在生物信息学中,索引技术、组合算法、统计、统计学习方法等诸多技艺各显神通,相信总能找到你感兴趣的地方,相信你的才华在我们组能够得到施展!
邬龙关于我们团队的介绍:
生物信息学是一个交叉学科,其中有很多新问题。机器学习、统计和算法设计方面的知识在这个领域非常重要。pFind团队有十年积累,这给团队未来的发展打下了坚实的基础。如果你信仰科学并且热爱算法,那么你将在pFind团队展开一段灿烂的人生旅程!等待你的关键词是:大数据、集群计算、算法、统计机器学习!
何昆关于我们团队的介绍:
图灵思索奶牛体表的花斑的形成开启了对混沌和自组织研究的先河,冯诺依曼更是如流星一般划过众多的研究领域。任何一个领域都不缺乏机会,而是缺乏洞见。优秀的思维能力,良好的数学基础,会让你在生物信息学领域有所发现。欢迎有科学梦想,有深刻思维的同学报考pFind。
孟佳明关于我们团队的介绍:
我是一名2011级入学的pFinder,目前在组内负责pLink软件的改进工作,期望软件在速度与精度上都能有进一步的提升,能够继续保持在双肽段交联鉴定方面的国际最好水平。pLink软件是pFind组多年潜心蛋白质序列鉴定的一项突破性的研究进展,相关论文于2012年发表在Nature Methods,影响因子23.565。这项工作组内的第一作者是高我硕士一轮的吴妍洁师姐,她硕士毕业后就职于摩根士丹利。我入学时师姐已毕业未能一起工作、学习,不过她的聪明才智在其硕士论文中得以窥探到。我进组后在组内师兄帮助下,半年内能够迅速掌握领域内的基本概念与基本问题,特别是邬龙师兄带我掌握了质谱鉴定的基本流程,樊盛博师兄帮助我快速地了解了pLink,迟浩师兄是目前pFind版本核心流程的缔造者,每次有什么问题与他交流后总能够想到更多的思路,他在算法与软件工程方面都有着丰富的经验。pFind是一个强大的团队,他的每一项工作都是团队共同合作的成果,大家平时午餐与晚餐时常聚在一起,这些潜移默化的交流与接触,可以让你更快的融入这个团队,也能够让你尽情地发挥你的所长,团队中有参加过ACM擅长算法的,也有喜爱软件工程的,还有爱好钻研数学的,总之在这个团队中你能够成长更快,学习更多。不过组内的要求也是严格的,组内几乎每位毕业的硕士都会有一篇SCI文章发表,如果你相信自己,pFind组会是一个不错的选择,在这里的经历也会成为你人生中宝贵的财富。
刘超的说明:佳明做事规整、有条理,硕士毕业后,在亚马逊工作。附:孟佳明同学关于自己做科研和找工作的感悟,欢迎大家下载观看。
罗兰关于我们团队的介绍:
我加入pFind团队一年了,转眼间已由小师妹变成了大师姐。在pFind团队的这一年里老师和师兄们花了大量精力给我们几个新生做了系统的培训。这种新生培训能够让我们迅速地了解研究背景、找到自己的用武之地并快速成长为真正的pfinder。过去的一年我得到了很多师兄们的帮助,也从老师和师兄们那里学到了很多,不仅有本领域的专业知识,更有踏实严谨的科研作风。pFind团队是一个非常容易融入的大家庭,欢迎有兴趣有勇气的同学加入我们!
杨皓关于我们团队的介绍:
我想说的是我们不是搞生物的,而是搞计算的。计算机的算法、组合数学、概率论与数理统计、机器学习等等,这些都是和计算机相关的学科,相信你能够找到一到二个自己感兴趣的方向,不会有任何的困难。欢迎大家热烈报名!
吴建强关于我们团队的介绍:
pFind真的是一个很融洽的小组,大家像兄弟一样。在这里你可以收获很多很多!我们组注重学生各个方面的培养,基础知识、学术能力、研发能力、人文修养,这个都可以有!欢迎报考...
陈镇霖关于我们团队的介绍:
我是2021年刚毕业的pFinder,很感谢在pFind团队度过了难忘的六年时光。pFind团队是一个追求卓越、勇攀高峰的团队,历经近20年的上下求索,团队在计算蛋白质组学领域取得了一系列重要突破,在国际舞台上发出了中国最强音。虽然取得了一定的成绩,但团队成员仍然秉持着“永远创业”的精神,组里的老师也仍然奋战在科研一线,所有pFinders都在为攀登下一个高峰而努力奋斗。如果你不畏艰难、锐意进取,欢迎你加入pFind团队。在这里,你会经历科研受挫的痛苦,也能感受科研成功的喜悦。相信经过pFind组的磨练,你会变得更加强大。欢迎对信息检索、机器学习和生物信息等方向感兴趣的同学加入我们。